HTTP 0.9 and the Origins of the Web

Learning new technologies can be extremely fun…extremely frustrating, but overall always a great time. Over the course of the past few years on my journey to learning as much as I can about the modern day web, I’ve picked up some really awesome skills. From web crawling in Ruby, to AJAX requests in JavaScript there really are a seemingly infinite amount of interesting topics for the modern day web developer to dive into. It seems the deeper you get, the more interesting the the internet and related technologies become.
When learning something new I tend to take a top-down approach. I like to get
something working from a very high level and then dig deeper and slowly pry
apart the different layers until I have a solid understanding of how it works.
I remember when i first learned how to make AJAX requests in JQuery. I didn’t
care how I was magically requesting data asynchronously using convenience
methods like $.getJSON(). I just thought it was super cool I could fetch the
surf forecast and log it to my console (thanks magicseaweed.com). It wasn’t
until later, once I had a solid grasp of the whole async thing that I wanted to
know how it actually worked underneath the hood. So, as I always have, I swam
down a layer and learned all about the browsers’ XMLHttpRequest API. This
seems to be a recurring pattern in my learning.
When I first began my quest to learn javascript, this same pattern presented itself. I skimmed a book or two and immediately began building side projects. At first gradually adding the language to previous web apps of mine, then exploring the html5 device apis, to building some chrome extensions, playing with Node.js and on and on… One day I stumbled across a series of lectures from Douglas Crockford on the history and future of JavaScript. I clearly remember wanting to learn more and more about the history of the language and how we got to where we are today with JavaScript - excuse me, ECMAScript. Since then I have enjoyed learning the history of other major web technologies. A particular one of interest to me is HTTP, which is essentially the main language, or protocol, computers connected to the web use to speak to each other. Sir Tim Berners-Lee developed HTTP as a simple, one line protocol to allow computers to request, as well as respond to one another with hypertext documents. Although HTTP 0.9 was introduced in 1991, we can still play with it today (using telnet given the server supports HTTP 0.9 ). I find this to be a great way to truly understand how much the protocol has developed.
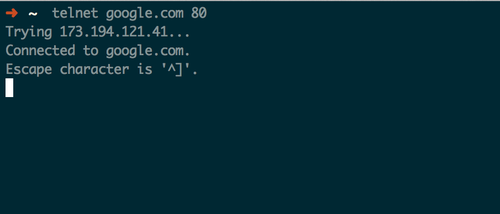
We hop on our command line and begin by openning a TCP connection on port 80:
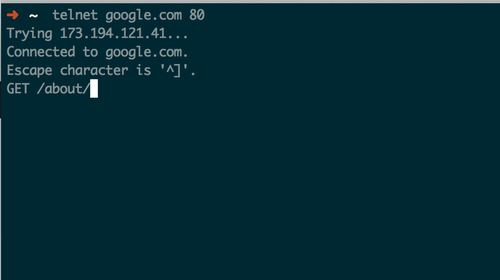
Then we send an HTTP GET request followed by the resource
As a response we get a pure HTML document representation! That is it! We get no headers or meta data, just an HTML document.
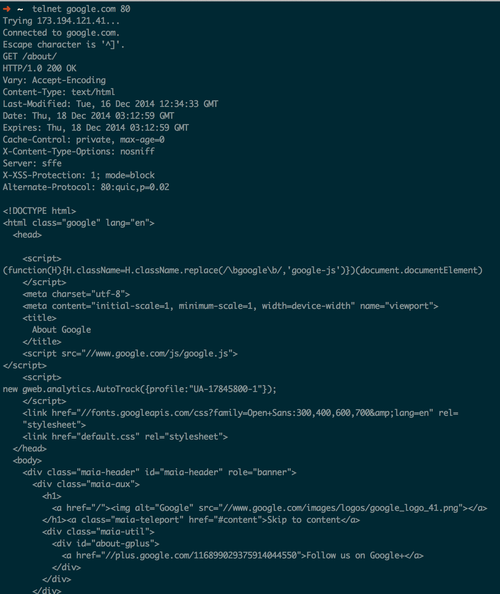
I thought it was pretty cool reading through the response from the command line. I can’t imagine how pumped Tim and the team must have been when they saw something like this for the first time.

Of course, now clients can request and servers can respond in various formats and media types, however this is where it all started and I think it is pretty damn cool. I encourage any person with a passion to dive deeper into what it is they are truly interested in. If it is the internet, then you’re very lucky because there is so much cool stuff out there. However, your passion could be surfing (another one of mine) or video games, or really whatever - as long as you’re having fun that’s rad! If anything this is just a testament to how much the internet has changed since its inception nearly 20 years ago. And I can’t wait for the next 20!
Now I should probably get back to studying for my data structures final tomorrow.